Encontrar Clusters de Ponto
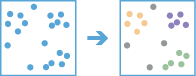
A ferramenta Encontrar Clusters de Ponto encontra agrupamentos de elementos de pontos em ruído circundante com base na respetiva distribuição espacial ou espaçotemporal.
Por exemplo, uma organização não-governamental está a estudar uma doença específica transmitida por parasita. Possui um conjunto de dados de ponto que representa agregados familiares numa área de estudo, estando algumas infestadas e outras não. Ao utilizar a ferramenta Encontrar Clusters de Ponto , um analista pode determinar clusters de agregados familiares infestados para ajudar a definir uma área na qual iniciar o tratamento e a exterminação dos parasitas.
Selecione a camada a partir da qual os clusters serão encontrados.
A camada de pontos em que se encontrarão os agrupamentos. As camadas têm de encontrar-se numa referência espacial projetada ou a referência espacial de processamento tem de ser definida para um sistema de coordenadas projetado que utilize os Ambientes de Análise.
Para além de escolher uma camada do seu mapa, pode escolher Escolher Camada de Análise na parte inferior da lista pendente para navegar até aos seus conteúdos de um conjunto de dados de partilha de ficheiros de big data ou camada de elementos. Opcionalmente, pode aplicar um filtro na sua camada de entrada ou aplicar uma seleção em camadas alojadas adicionadas ao seu mapa. Os filtros e seleções são aplicados apenas para análise.
Escolha o método de agrupamento a usar
O método de agrupamento que será utilizado para distinguir agrupamentos de elementos de pontos de ruído circundante. Pode optar por utilizar uma distância definida ou um algoritmo de agrupamento autoajustável.
A distância definida (DBSCAN) utiliza um intervalo de pesquisa especificado para separar agrupamentos densos de ruído disperso. Opcionalmente, pode ser utilizado tempo para encontrar agrupamentos espaçotemporais utilizando um intervalo e uma duração de pesquisa. A distância definida (DBSCAN) é mais rápida, mas apenas é adequada se houver um intervalo de pesquisa muito claro a utilizar que funcione bem para definir todos os agrupamentos que possam estar presentes. A distância definida (DBSCAN) encontra agrupamentos que têm densidades similares.
O ajuste automático (HDBSCAN) não necessita que se especifique um intervalo de pesquisa, mas é um método mais demorado. O ajuste automático (HDBSCAN) encontra agrupamentos de pontos semelhantes à distância definida (DBSCAN), mas utiliza intervalos de pesquisa variáveis, permitindo agrupamentos com densidades variáveis.
Número mínimo de pontos para criar um agrupamento
Este parâmetro é utilizado de forma diferente, dependendo do método de agrupamento escolhido:
- Distância definida (DBSCAN) — especifica o número de elementos que têm de ser encontrados a uma certa distância e duração de um ponto para que esse ponto comece a formar um agrupamento. A distância é definida utilizando o parâmetro Limitar o intervalo de pesquisa para. Se o tempo for utilizado para descobrir agrupamentos espaçotemporais, a duração é especificada através do parâmetro Limitar a duração da pesquisa.
- Ajuste automático (HDBSCAN) — especifica o número de elementos que circundam cada ponto (incluindo o próprio ponto) que serão considerados ao estimar a densidade. Este número também é o tamanho mínimo de agrupamento permitido ao extrair agrupamentos.
Limite o intervalo de pesquisa para
Ao utilizar a distância definida (DBSCAN), este parâmetro é a distância dentro da qual o Número mínimo de pontos para compor um agrupamento tem de ser encontrado. Se a camada de entrada possui uma componente de tempo ativa e for do tipo instante, pode selecionar Utilizar tempo para encontrar agrupamentos para descobrir grupos espaçotemporais de pontos no ruído circundante. Utilizando o tempo, o parâmetro Limitar a duração da pesquisa para especifica a duração na qual o Número mínimo de pontos para compor um agrupamento deve ser encontrado para além de estar dentro do intervalo de pesquisa. Estes parâmetros não são utilizados quando o ajuste automático (HDBSCAN) é escolhido como o método de agrupamento a utilizar.
Nome da camada resultante
O nome da camada que será criada. Se estiver a escrever para ArcGIS Data Store, os seus resultados serão guardados em O Meu Conteúdo e adicionados ao mapa. Se estiver a escrever para uma partilha de ficheiros big data, os seus resultados serão guardados na partilha de ficheiros big data e adicionados ao seu manifesto. Não serão adicionados ao mapa. O nome padrão é baseado no nome da ferramenta e do nome da camada de entrada. Caso a camada já existe, a ferramenta irá falhar.
Ao escrever para ArcGIS Data Store (armazenamento relacional ou espaciotemporal de dados big data) utilizando a caixa suspensa Guardar resultado em pode especificar o nome de uma pasta em O Meu Conteúdo, onde será armazenado o resultado.