Encontrar Localizações de Intervalo
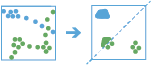
Esta ferramenta funciona com uma camada com componente de tempo ativa de elementos de ponto de tipo instante. Primeiro, esta ferramenta atribui elementos a um trilho utilizando um identificador único. A ordem do trilho é determinada pela hora dos elementos. Em seguida, é calculada a distância entre a primeira observação num trilho e a próxima. Os elementos são considerados como parte de um intervalo se dois pontos temporariamente consecutivos se situarem dentro de uma determinada distância pelo menos durante o tempo determinado. Quando dois elementos se encontrarem num intervalo, o primeiro elemento no intervalo é utilizado como ponto de referência, e a ferramenta encontra elementos consecutivos que se encontram dentro de uma distancia especificada do ponto de referência no intervalo. Assim que forem encontrados todos os elementos dentro da distância especificada, a ferramenta recolhe todos os elementos do intervalo e calcula o centro médio. Os elementos antes e depois do intervalo atual são adicionados ao intervalo se se encontraram dentro de uma determinada distância do centro médio da localização do intervalo. Este processo continua até ao final do trilho.
Os elementos em camadas com componente temporal ativa podem ser representados por uma das seguintes formas:
- Instante—um momento único no tempo
- Intervalo—Uma hora de início e de fim
Por exemplo, suponha que trabalha no Departamento de Transportes e recolheu leituras de GPS para veículos em vias rodoviárias importantes. Cada registo de GPS contém uma ID de veículo única, a hora, a localização e a velocidade. Utilizando a ID de veículo única para definir trilhos individuais, procure veículos que não se moveram mais de 100 metros em pelo menos 15 minutos para descobrir zonas problemáticas na rede rodoviária. Adicionalmente, pode calcular estatísticas tais como a velocidade média dos veículos dentro da localização de intervalo.
Escolher a camada para encontrar intervalos
A camada de ponto que será resumida em intervalos. A camada de entrada tem de ter a componente temporal ativa com elementos que representam um instante no tempo, bem como ter um ou mais campos que podem ser utilizados para identificar trilhos.
Para além de escolher uma camada do seu mapa, pode escolher Escolher Camada de Análise na parte inferior da lista pendente para navegar até aos seus conteúdos de um conjunto de dados de partilha de ficheiros de big data ou camada de elementos. Opcionalmente, pode aplicar um filtro na sua camada de entrada ou aplicar uma seleção em camadas alojadas adicionadas ao seu mapa. Os filtros e seleções são aplicados apenas para análise.
Selecionar um ou mais campos para identificar trilhos
Os campos que representam o identificador de trilhos. Pode utilizar um campo ou vários campos para representar valores únicos de trilhos.
Por exemplo, caso estivesse a procurar localizações de Intervalo para furacões, poderia utilizar o nome do furacão como campo de trilho.
Escolher método para calcular distância
Método utilizado para calcular a distância do intervalo dentro de trilhos. O método Planar pode calcular os resultados mais rapidamente, mas não irá associar os trilhos à linha de data internacional, ou considerar o verdadeiro formato da Terra ao aplicar buffers. O método Geodésico irá associar os trilhos à linha de data internacional, se necessário, e aplicar um buffer geodésico para considerar o formato da Terra.
Definir distância de pesquisa espacial
A tolerância do intervalo é a distância máxima entre pontos a considerar numa única localização de intervalo.
Por exemplo, se está interessado em encontrar intervalos onde o trânsito não se tenha movido mais do que 20 metros num determinado período, a tolerância da distância seria de 20 metros.
Utilize o parâmetro Definir intervalo de pesquisa temporal para especificar o tempo.
Divisão de Trilhos (opcional)
A unidade de tolerância da distância.
Definir intervalo de pesquisa temporal
A tolerância de tempo de intervalo é o tempo mínimo entre um intervalo a considerar numa única localização de intervalo.
Por exemplo, se quiser saber onde o trânsito não se moveu uma determinada distancia durante uma hora, a tolerância de tempo seria 1 hora.
Utilize o parâmetro Definir intervalo de pesquisa espacial para especificar a distância.
Selecionar uma distância pela qual dividir trilhos (opcional)
A unidade de tolerância do tempo.
Adicionar estatísticas (opcional)
Pode calcular estatísticas em elementos que se encontram resumidos. Pode calcular o seguinte em campos numéricos:
- Contagem—Calcula o número de valores não-nulos. Pode ser utilizado em campos numéricos ou cadeias de caracteres. A contagem de [null, 0, 2] é 2.
- Soma—A soma dos valores numéricos num campo. A soma de [null, null, 3] é 3.
- Média—A média de valores numéricos. A média de [0, 2, null] é 1.
- Mín—o valor mínimo de um campo numérico. O mínimo de [0, 2, null] é 0.
- Máx—o valor máximo de um campo numérico. O valor máximo de [0, 2, null] é 2.
- Intervalo—o intervalo de um campo numérico. Este é calculado subtraindo os valores mínimos ao valor máximo. O intervalo de [0, null, 1] é 1. O intervalo de [null, 4] é 0.
- Variância—a variância de um campo numérico num trilho. A variância de [1] é null. A variância de [null, 1,0,1,1] é 0.25.
- Desvio padrão—O desvio padrão de um campo numérico. O desvio padrão de [1] é null. O desvio padrão de [null, 1,0,1,1] é 0.5.
- Primeiro — O primeiro valor de um campo especificado no trilho resumido. Se um trilho tem os seguintes valores ordenados por tempo para um campo: [1,5,10,20], o primeiro valor é 1.
- Último — O último valor de um campo especificado no trilho resumido. Se um trilho tem os seguintes valores ordenados por tempo para um campo: [1,5,10,20], o último valor é 20.
Pode calcular o seguinte em campos de cadeias de caracteres:
- Contagem—O número de strings não-nulas.
- Qualquer—Esta estatística é uma amostra aleatória de um valor de string no campo especificado.
- Primeiro — O primeiro valor de um campo especificado no trilho resumido. Se um trilho tem os seguintes valores ordenados por tempo para um campo: [Toronto,Guelph,Squamish,Montreal,Halifax,Redlands,Boston], o primeiro valor é Toronto.
- Último — O último valor de um campo especificado no trilho resumido. Se um trilho tem os seguintes valores ordenados por tempo para um campo: [Toronto,Guelph,Squamish,Montreal,Halifax,Redlands,Boston], o último valor é Boston.
Fornecer localizações de intervalo como
Determina que elementos são devolvidos e o formato. Estão disponíveis quatro tipos:
- Centros Médios — Um ponto que representa o centroide de cada localização de intervalo descoberto. Os atributos serão resumidos. Isto é por omissão.
- Fechos Convexos — Polígonos que representam o fecho convexo de cada grupo de intervalo. Os atributos serão resumidos.
- Elementos de Intervalo — Todos os elementos e atributos de pontos de entrada que se determinou pertencerem a um intervalo são devolvidos.
- Todos os Elementos — Todos os elementos e atributos de pontos de entrada são devolvidos.
Analisar dados com intervalos de tempo (opcional)
Especifique se pretende detetar localizações de Intervalo utilizando intervalos de tempo que segmentam os seus elementos de entrada para análise. Se utiliza intervalos de tempo tem de definir o intervalo de tempo que pretende utilizar, e opcionalmente definir o momento de referência. Se não definir um momento de referência será utilizado 1 de janeiro de 1970.
Por exemplo, se definir que o limite de tempo é de 1 dia, começando às 9:00 AM de 1 de janeiro de 1990, então cada trilho será truncado às 9:00 AM de cada dia e analisado dentro desse segmento. Nenhum intervalo antes das 09:00 e terminará depois.
Utilizar intervalos de tempo é uma forma rápida de acelerar o tempo de cálculo, visto que isso cria rapidamente trilhos mais pequenos para análise. Se a divisão por um intervalo de tempo recorrente faz sentido para a sua análise, isso é recomendado para o processamento de big data.
Nome da camada resultante
O nome da camada que será criada. Se estiver a escrever para ArcGIS Data Store, os seus resultados serão guardados em O Meu Conteúdo e adicionados ao mapa. Se estiver a escrever para uma partilha de ficheiros big data, os seus resultados serão guardados na partilha de ficheiros big data e adicionados ao seu manifesto. Não serão adicionados ao mapa. O nome padrão é baseado no nome da ferramenta e do nome da camada de entrada. Caso a camada já existe, a ferramenta irá falhar.
Ao escrever para ArcGIS Data Store (armazenamento relacional ou espaciotemporal de dados big data) utilizando a caixa suspensa Guardar resultado em pode especificar o nome de uma pasta em O Meu Conteúdo, onde será armazenado o resultado.