Trova posizione dell'abitazione
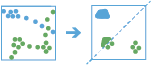
Questo strumento funziona con un layer abilitato per variazioni temporali di feature puntuali di tipo istante. In primo luogo, lo strumento assegna le feature a una traccia utilizzando un identificatore univoco. L'ordine di traccia è determinato dal tempo delle feature. Successivamente, viene calcolata la distanza tra la prima osservazione in una traccia e la successiva. Le feature sono considerate parte di un'abitazione se due punti temporalmente consecutivi rimangono entro una determinata distanza per almeno la durata data. Quando due feature vengono rilevate come parte di un'abitazione, la prima feature nell'abitazione viene utilizzata come punto di riferimento e lo strumento trova feature consecutive entro la distanza specificata dal punto di riferimento nell'abitazione. Una volta trovate tutte le feature entro la distanza specificata, lo strumento raccoglie le feature dell'abitazione e calcola il loro centro medio. Le feature prima e dopo l'abitazione corrente vengono aggiunte all'abitazione se si trovano entro una determinata distanza dal centro medio della posizione dell'abitazione. Questo processo continua fino alla fine della traccia.
Le feature abilitate per variazioni temporali possono essere rappresentate in uno dei modi diversi:
- Istante: per un singolo momento di tempo
- Intervallo: un'ora d'inizio e un'ora di fine
Ad esempio, si supponga di lavorare per il Dipartimento dei trasporti e di aver raccolto i valori GPS per i veicoli sulle principali autostrade. Ogni record GPS contiene un ID univoco del veicolo, l'ora, la posizione e la velocità. Utilizzando l'ID univoco del veicolo per definire le singoli tracce, cercare i veicoli che non si sono mossi di oltre 100 metri in almeno 15 minuti per scoprire aree problematiche nella rete stradale. Inoltre, è possibile calcolare statistiche come la velocità media dei veicoli entro il luogo dell'abitazione.
Scegliere il layer nel quale verranno trovate le abitazioni
Il layer puntuale che verrà riepilogato nelle abitazioni. Il layer di input deve essere abilitato per variazioni temporali con feature che rappresentano un istante nel tempo e dispone di uno o più campi che possono essere utilizzati per identificare tracce.
Oltre a scegliere un layer dalla mappa, è possibile selezionare Scegli layer di analisi alla base dell'elenco a discesa per cercare un dataset di condivisione file Big Data o un feature layer. In via facoltativa, è possibile applicare un filtro al layer di input o applicare una selezione sul layer hosted aggiunto alla mappa. I filtri e le selezioni vengono applicati solo per l'analisi.
Selezionare uno o più campi per identificare le tracce
I campi che rappresentano l'identificatore di tracce. È possibile utilizzare uno o più campi per rappresentare valori univoci delle tracce.
Ad esempio, se si stanno rilevando posizioni dell'abitazione per uragani, si dovrebbe usare il nome dell'uragano come campo della traccia.
Scegliere il metodo per il calcolo della distanza
Metodo utilizzato per calcolare la distanza dell'abitazione all'interno di tracce. Il metodo Planare consente di calcolare i risultati più velocemente ma non unisce le tracce in corrispondenza della linea di cambio data internazionale né tiene in considerazione la forma effettiva della terra durante il buffering. Il metodo Geodetico consente di unire le tracce in corrispondenza della linea di cambio data internazionale e applica un buffer geodetico tenendo in considerazione la forma effettiva della terra.
Definire la distanza di ricerca spaziale
La tolleranza della distanza dell'abitazione è la distanza massima tra i punti da considerare in una singola posizione dell'abitazione.
Ad esempio, se si è interessati a trovare abitazioni in cui il traffico non si è spostato di oltre 20 metri in un determinato periodo, la tolleranza della distanza sarebbe di 20 metri.
Utilizzare il parametro Definire l'intervallo di ricerca temporale per specificare l'ora.
Suddividi tracce (opzionale)
Unità di tolleranza della distanza.
Definire l'intervallo di ricerca temporale
La tolleranza del tempo dell'abitazione è la durata minima di un'abitazione da considerare in una singola posizione dell'abitazione.
Ad esempio, se si desidera sapere il punto in cui il traffico non si è spostato di una determinata distanza entro un'ora, la tolleranza del tempo sarebbe di 1 ora.
Utilizzare il parametro Definire l'intervallo di ricerca spaziale per specificare la distanza.
Selezionare una distanza per suddividere le tracce (facoltativo)
Unità di tolleranza del tempo.
Aggiungi statistiche (facoltativo)
È possibile calcolare le statistiche su feature riepilogate. Su campi numerici è possibile calcolare quanto segue:
- Conteggio: calcola il numero di valori nonnull. Può essere utilizzato su campi o stringhe numeriche. Il conteggio di [null, 0, 2] è 2.
- Somma: la somma dei valori numerici in un campo. La somma di [null, null, 3] è 3.
- Media: la media di valori numerici. La media di [0, 2, null] è 1.
- Min: il valore minimo di un campo numerico. Il minimo di [0, 2, null] è 0.
- Max: il valore massimo di un campo numerico. Il valore massimo di [0, 2, null] è 2.
- Intervallo: l'intervallo di un campo numerico. Questo viene calcolato come i valori minimi sottratti dal valore massimo. L'intervallo di [0, null, 1] è 1. L'intervallo di [null, 4] è 0.
- Varianza: la varianza di un campo numerico in una traccia. La varianza di [1] is null. La varianza di [null, 1, 0, 1, 1] è 0,25.
- Deviazione standard: la deviazione standard di un campo numerico. La deviazione standard di [1] è null. La deviazione standard di [null, 1, 0, 1, 1] è 0,5.
- Primo: il primo valore di un campo specificato nella traccia di riepilogo. Se una traccia ha i seguenti valori ordinati per tempo per un campo: [1, 5, 10, 20], il primo valore è 1.
- Ultimo: l'ultimo valore di un campo specificato nella traccia di riepilogo. Se una traccia ha i seguenti valori ordinati per tempo per un campo: [1, 5, 10, 20], l'ultimo valore è 20.
Su campi stringa è possibile calcolare quanto segue:
- Conteggio: il numero di stringhe nonnull.
- Qualsiasi: questa statistica è un esempio casuale di un valore stringa nel campo specificato.
- Primo: il primo valore di un campo specificato nella traccia di riepilogo. Se una traccia ha i seguenti valori ordinati per tempo per un campo: [Toronto, Guelph, Squamish, Montreal, Halifax, Redlands, Boston], il primo valore è Toronto.
- Ultimo: l'ultimo valore di un campo specificato nella traccia di riepilogo. Se una traccia ha i seguenti valori ordinati per tempo per un campo: [Toronto, Guelph, Squamish, Montreal, Halifax, Redlands, Boston], l'ultimo valore è Boston.
Eseguire l'output delle posizioni delle abitazioni come
Determina quali feature vengono restituite e il formato. Sono disponibili quattro tipi:
- Centri medi: un punto che rappresenta il centroide di ciascuna posizione di abitazione rilevata. Gli attributi vengono riepilogati. Questa è l'impostazione predefinita.
- Involucri convessi: poligoni che rappresentano l'involucro convesso di ciascun gruppo di abitazione. Gli attributi vengono riepilogati.
- Feature abitazioni: vengono restituite tutte le feature puntuali di input e gli attributi determinati come appartenenti a un'abitazione.
- Tutte le feature: vengono restituite tutte le feature puntuali di input e gli attributi.
Analizzare dati con intervalli di tempo (opzionale)
Specificare se si desidera rilevare le posizioni delle abitazioni usando intervalli di tempo che segmentano le feature di input per l'analisi. Se si utilizzano intervalli di tempo, è necessario impostare l'intervallo di tempo da usare e, facoltativamente, impostare un riferimento temporale. Se non si imposta un riferimento temporale, si userà il 1 gennaio 1970.
Ad esempio, se si imposta come confine temporale 1 giorno, a partire dalle 9:00 del 1º gennaio 1990, ogni traccia sarà troncata alle 9:00 di ogni giorno e analizzata all'interno di tale segmento. Nessuna abitazione inizierà prima delle 9:00 e finirà dopo.
L'utilizzo di intervalli di tempo è un modo rapido per accelerare il tempo di calcolo, perché crea rapidamente tracce più piccole per l'analisi. Se per l'analisi è conveniente dividere in base a un intervallo di tempo ricorrente, si consiglia per l'elaborazione di Big Data.
Nome del layer dei risultati
Il nome del layer che verrà creato. Se si scrive su un ArcGIS Data Store, i risultati saranno salvati in I miei contenuti e aggiunti alla mappa. Se si scrive su una condivisione file Big Data, i risultati saranno memorizzati nella condivisione file Big Data e aggiunti al suo Manifest. Non saranno aggiunti alla mappa. Il nome predefinito è basato sul nome dello strumento e sul nome del layer di input. Se il layer esiste già, lo strumento non verrà eseguito.
Quando si scrive su ArcGIS Data Store (data store relazionale o Spatiotemporal Big Data Store) usando la casella a discesa Salva risultato in, è possibile specificare il nome di una cartella in I miei contenuti in cui salvare il risultato.