Synthétiser - A l’intérieur
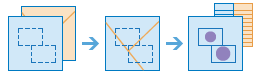
Cet outil recherche les entités (et parties d'entités) qui se trouvent au sein des limites des surfaces dans la première couche en entrée.
- En prenant une couche de limites de bassin versant et une couche de limites d'utilisation du sol, calculez la superficie totale du type d'utilisation du sol pour chaque bassin versant.
- En prenant une couche de parcelles dans un comté et une couche de limites de ville, synthétisez la valeur moyenne des parcelles vacantes au sein de chaque limite de ville.
Si l'option Utiliser l'étendue courante de la carte est sélectionnée, seules les entités de la couche en entrée et de la couche à synthétiser qui sont visibles au sein de l'étendue courante de la carte seront analysées. Si l'option n'est pas sélectionnée, toutes les entités qui se trouvent à la fois dans la couche en entrée et dans la couche à synthétiser seront analysées, même si elles se trouvent en dehors de l'étendue courante de la carte.
Choisissez une couche surfacique pour synthétiser d'autres entités au sein de ses limites
La couche surfacique qui sera utilisée pour synthétiser des entités comprises au sein de ses limites. Vous pouvez procéder à une synthèse dans une couche de polygones que vous spécifiez ou dans des groupes hexagonaux ou carrés qui sont générés pendant l'exécution de l'outil. Lors de la génération des groupes, pour Carré, le nombre et les unités spécifiés déterminent la hauteur et la longueur du carré. Pour Hexagone, le nombre et les unités spécifiés déterminent la distance entre les côtés parallèles.
L'analyse à l’aide de groupes carrés ou hexagonaux requiert un système de coordonnées projetées. Vous pouvez définir le système de coordonnées de traitement dans des environnements d’analyse. Si votre système de coordonnées de traitement n’est pas défini sur un système de coordonnées projetées, vous êtes invité à le configurer lorsque vous exécutez l’analyse .
En plus de choisir une couche de votre carte, vous pouvez sélectionner Choose Analysis Layer (Choisir une couche d’analyse) au bas de la liste déroulante pour parcourir votre contenu et rechercher une couche d’entités ou un jeu de données de partage de fichiers Big Data. Vous pouvez appliquer un filtre à votre couche en entrée ou appliquer une sélection aux couches hébergées ajoutées à votre carte. Les filtres et les sélections sont uniquement appliqués à des fins d’analyse.
Choisir la couche à synthétiser
Les entités de cette couche qui se trouvent au sein des limites des entités de la couche en entrée, ou les groupes spécifiés ci-dessus, seront synthétisés.
En plus de choisir une couche de votre carte, vous pouvez sélectionner Choose Analysis Layer (Choisir une couche d’analyse) au bas de la liste déroulante pour parcourir votre contenu et rechercher une couche d’entités ou un jeu de données de partage de fichiers Big Data. Vous pouvez appliquer un filtre à votre couche en entrée ou appliquer une sélection aux couches hébergées ajoutées à votre carte. Les filtres et les sélections sont uniquement appliqués à des fins d’analyse.
Choisir une distance pour générer les groupes et dans laquelle effectuer l'agrégation
Distance utilisée pour générer des groupes.
Vous devez définir les options Bin Size (Taille du groupe) pour les groupes ou Area Layer (Couche surfacique).
Agréger à l'aide des tranches horaires (facultatif)
Si le temps est activé sur la couche ponctuelle en entrée et qu'il est de type instantané, vous pouvez effectuer l'analyse à l'aide des intervalles temporels. Vous pouvez définir trois paramètres lorsque vous utilisez le temps :
- Intervalle temporel
- Fréquence de répétition de l'intervalle
- Heure sur laquelle aligner les intervalles temporels
Par exemple, si vous avez des données représentant une année et que vous souhaitez les analyser par intervalles hebdomadaires, définissez Time step interval (Intervalle temporel) sur 1 week (1 semaine).
Par exemple, si vous avez des données représentant une année et que vous souhaitez les analyser à l’aide de la première semaine du mois, définissez Time step interval (Intervalle temporel) sur 1 week (1 semaine), How often to repeat the time step (Fréquence de répétition de l’intervalle) sur 1 month (1 mois), puis Time to align the time steps to (Heure sur laquelle aligner les intervalles temporels) sur January 1, at 12:00 am (1er janvier à 12 h 00).
Intervalle temporel dans lequel effectuer l'agrégation
L’intervalle de temps utilisé pour générer des intervalles temporels. Vous pouvez utiliser Time step interval (Intervalle temporel) seul ou avec le paramètre How often to repeat the time step (Fréquence de répétition de l’intervalle) ou Time to align the time steps to (Heure sur laquelle aligner les intervalles temporels).
Par exemple, pour créer des intervalle temporels qui ont lieu tous les lundis de 9 h 00 à 10 h 00, définissez Time step interval (Intervalle temporel) sur 1 hour (1 heure), How often to repeat the time step (Fréquence de répétition de l’intervalle) sur 1 week (1 semaine) et Time to align the time steps to (Heure sur laquelle aligner les intervalles temporels) sur 9:00:00 a.m. on a Monday (9 h 00 un lundi).
Phase dans laquelle effectuer l'agrégation
Intervalle utilisé pour calculer un intervalle. Vous pouvez utiliser le paramètre How often to repeat the time step (Fréquence de répétition de l’intervalle) seul ou avec Intervalle temporel, avec Time step interval (Heure de référence), ou avec à la fois Time step interval (Intervalle temporel) et Time to align the time steps to (Heure sur laquelle aligner les intervalles temporels).
Par exemple, pour créer des intervalle temporels qui ont lieu tous les lundis de 9 h 00 à 10 h 00, définissez Time step interval (Intervalle temporel) sur 1 hour (1 heure), How often to repeat the time step (Fréquence de répétition de l’intervalle) sur 1 week (1 semaine) et Time to align the time steps to (Heure sur laquelle aligner les intervalles temporels) sur 9:00:00 a.m. on a Monday (9 h 00 un lundi).
Heure de référence permettant d'aligner les tranches horaires
La date et l'heure utilisées pour aligner les tranches horaires. Les intervalles temporels commencent à partir de cette heure et progressent vers le passé. Si aucune heure de référence n'est sélectionnée, les intervalles temporels s'alignent sur le 1er janvier 1970.
Par exemple, pour créer des intervalle temporels qui ont lieu tous les lundis de 9 h 00 à 10 h 00, définissez Time step interval (Intervalle temporel) sur 1 hour (1 heure), How often to repeat the time step (Fréquence de répétition de l’intervalle) sur 1 week (1 semaine) et Time to align the time steps to (Heure sur laquelle aligner les intervalles temporels) sur 9:00:00 a.m. on a Monday (9 h 00 un lundi).
Ajouter des statistiques (facultatif)
Vous pouvez calculer des statistiques sur des entités synthétisées. Vous pouvez calculer les données suivantes sur des champs numériques :
- Total : calcule le nombre de valeurs non Null. Peut être utilisé sur des champs numériques ou des chaînes. Le total de [Null, 0, 2] est égal à 2.
- Somme : somme des valeurs numériques dans un champ. La somme de [Null, 0, 3] est égale à 3.
- Moyenne : moyenne des valeurs numériques. La moyenne de [0, 2, Null] est égale à 1.
- Min : valeur minimale d'un champ numérique. La valeur minimale de [0, 2, Null] est égale à 0.
- Max : valeur maximale d'un champ numérique. La valeur maximale de [0, 2, Null] est égale à 2.
- Plage : plage d'un champ numérique. Elle est calculée pour correspondre aux valeurs minimales soustraites de la valeur maximale. La plage de [0, Null, 1] est égale à 1. La plage de [Null, 4] est égale à 0.
- Variance : variance d'un champ numérique dans une piste. La variance de [1] est la valeur Null. La variance de [null, 1,0,1,1] est égale à 0,25.
- Ecart type : écart type d'un champ numérique. L'écart type de [1] est la valeur Null. L’écart type de [null, 1,0,1,1] est égale à 0,5.
Vous pouvez calculer les données suivantes sur des champs de type chaîne :
- Total : le nombre de chaînes différentes de la valeur Null.
- Tout : cette statistique est un échantillon aléatoire d'une valeur de chaîne dans le champ spécifié.
Outre ces statistiques, des statistiques proportionnelles seront calculées sur tous les champs numériques :
- Total : total de chaque champ multiplié par la proportion de la couche de synthèse figurant dans les polygones.
- Somme : somme des valeurs pondérées de chaque champ. Lorsque la pondération appliquée correspond à la proportion de la couche de synthèse figurant dans les polygones.
- Moyenne : moyenne pondérée des valeur de chaque champ. Lorsque la pondération appliquée correspond à la proportion de la couche de synthèse figurant dans les polygones.
- Min : minimum des valeurs pondérées de chaque champ. Lorsque la pondération appliquée correspond à la proportion de la couche de synthèse figurant dans les polygones.
- Max : maximum des valeurs pondérées de chaque champ. Lorsque la pondération appliquée correspond à la proportion de la couche de synthèse figurant dans les polygones.
- Plage : différence entre les valeurs pondérées maximum et minimum.
Selon les types d'entités que vous synthétisez, le nombre total de points à proximité, la longueur totale des lignes ou la surface totale seront calculés.
Choisir le champ de regroupement
Il s'agit d'un attribut des entités à synthétiser qui permet de calculer les statistiques séparément pour chaque valeur attributaire unique. Supposons par exemple que la première couche en entrée contiennent les limites de ville et que les entités à synthétiser soient des parcelles. L’un des attributs des parcelles est Status. Il contient deux valeurs : VACANT et OCCUPIED. Pour calculer la surface totale des parcelles vacantes et occupées au sein des limites des villes, utilisez Status comme groupe par attribut. Les statistiques de chaque groupe, ainsi que le nombre total d'entités au sein de chaque limite de zone, apparaîtront dans la fenêtre contextuelle de la couche de résultat.
Ajouter une minorité, majorité
Cette case à cocher est activée lorsque vous sélectionnez un champ de regroupement. Si vous souhaitez savoir quelles valeurs attributaires au sein de chaque groupe sont minoritaires (les moins dominantes) ou majoritaires (les plus dominantes), dans chaque limite de la première couche en entrée, sélectionnez Ajouter la minorité et la majorité. Lorsque vous sélectionnez Ajouter la minorité et la majorité, deux nouveaux champs sont ajoutés à votre couche de résultat. Si vous sélectionnez également Ajouter des pourcentages, deux champs supplémentaires sont ajoutés à la couche de résultat, contenant les pourcentages des valeurs attributaires minoritaires et majoritaires au sein de chaque groupe.
- Si vous agrégez les points, les valeurs minoritaires et majoritaires sont calculées en fonction du nombre de points au sein de chaque zone adjacente dans la couche surfacique en entrée.
- Si vous agrégez les lignes, les valeurs minoritaires et majoritaires sont calculées en fonction de la longueur des lignes au sein de chaque zone adjacente dans la couche surfacique en entrée.
- Si vous agrégez les surfaces, les valeurs minoritaires et majoritaires sont calculées en fonction des surfaces au sein de chaque zone adjacente dans la couche surfacique en entrée.
Ajouter des pourcentages
Cette case à cocher est activée lorsque vous sélectionnez un champ de regroupement. Sélectionnez Add percentages (Ajouter des pourcentages) si vous souhaitez connaître le pourcentage de chaque valeur attributaire au sein de chaque groupe. Un nouveau champ est ajouté à la table de résultat ; il contient les pourcentages de chaque valeur attributaire au sein de chaque groupe. Si l’option Add minority, majority (Ajouter une minorité, majorité) est également sélectionnée, deux champs supplémentaires sont ajoutés à la couche de résultats ; ils contiennent les pourcentages des valeurs attributaires minoritaires et majoritaires au sein de chaque groupe.
Choisir un stockage des données
Les résultats GeoAnalytics sont stockés dans un répertoire de données et s’affichent en tant que couche d’entités dans Portal for ArcGIS. Dans la plupart des cas, les résultats doivent être stockés dans le stockage des données spatio-temporelles, ce qui est le paramètre par défaut. Dans certains cas, il peut être judicieux d’enregistrer les résultats dans un répertoire de données relationnelles. Voici les raisons pour lesquelles stocker les résultats dans le répertoire de données relationnelles :
- Vous pouvez utiliser vos résultats dans le cadre d’une collaboration entre plusieurs portails.
- Vous pouvez activer la synchronisation de vos résultats
Vous ne devez pas utiliser le répertoire de données relationnelles si vous pensez que vos résultats GeoAnalytics vont augmenter et que vous devez tirer parti des fonctionnalités du répertoire de Big Data spatio-temporelles pour gérer les grands volumes de données.
Nom de la couche de résultat
Le nom de la couche à créer. Si vous écrivez dans une instance ArcGIS Data Store, vos résultats sont enregistrés dans My Content (Mon contenu) et ajoutés à la carte. Si vous écrivez dans un partage de fichiers Big Data, vos résultats sont stockés dans le partage de fichiers Big Data et ajoutés à son manifeste. Ils ne sont pas ajoutés à la carte. Le nom par défaut repose sur le nom de l'outil et sur le nom de la couche en entrée. Si la couche existe déjà, l'outil échoue.
Lors de l’écriture sur ArcGIS Data Store (répertoire de données relationnelles ou spatio-temporelles) via la zone de liste déroulante Save result in (Enregistrer le résultat dans), vous pouvez spécifier le nom d’un dossier dans My Content (Mon contenu) où le résultat sera enregistré.