Créer des zones tampon
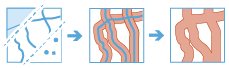
Une zone tampon est une surface qui couvre une distance donnée à partir d'une entité ponctuelle, linéaire ou surfacique.
Les zones tampon sont généralement utilisées pour créer des surfaces qui peuvent faire l'objet d'analyses plus approfondies à l'aide d'autres outils. Par exemple, si vous vous posez la question suivante : Quels sont les bâtiments qui se trouvent à moins d'un kilomètre de l'école ?, vous pouvez obtenir la réponse en créant une zone tampon d'un kilomètre autour de l'école et en superposant la zone tampon avec la couche contenant les emprises de bâtiments. Le résultat final est une couche des bâtiments qui se trouvent à moins d'un kilomètre de l'école.
Choisir la couche dans laquelle appliquer la zone tampon
Entités ponctuelles, linéaires ou surfaciques à buffériser. Les couches en entrée doivent se trouver dans un système de coordonnées projetées ou la référence spatiale de traitement doit être définie sur un système de coordonnées projetées à l'aide des environnements d'analyse.
En plus de choisir une couche de votre carte, vous pouvez sélectionner Choose Analysis Layer (Choisir une couche d’analyse) au bas de la liste déroulante pour parcourir votre contenu et rechercher une couche d’entités ou un jeu de données de partage de fichiers Big Data. Vous pouvez appliquer un filtre à votre couche en entrée ou appliquer une sélection aux couches hébergées ajoutées à votre carte. Les filtres et les sélections sont uniquement appliqués à des fins d’analyse.
Sélectionner le type de zone tampon à appliquer
Vous pouvez spécifier la taille de la zone tampon pour vos entités en entrée de trois façons :
- Indiquez une distance qui est appliquée à toutes les entités.
- Indiquez un champ dans la couche en entrée qui contient la valeur de distance. Vous pouvez utiliser un champ de chaîne ou un champ numérique. Si aucune unité linéaire n'est définie, les unités de la référence spatiale sont utilisées. Si vous utilisez un système de coordonnées géographiques, on suppose que le champ sans unité utilise les mètres.
- Générez une expression avec plusieurs champs et opérateurs mathématiques. Par exemple, pour buffériser 10 fois la valeur d’un champ nommé vitesse_vent, ajoutez l’expression $feature["vitesse_vent"] x 10.
Sélectionner la méthode de zone tampon
Vous pouvez utiliser une méthode planaire ou une méthode géodésique. La méthode planaire peut être plus rapide et convient à l'analyse locale sur des données projetées. La méthode géodésique convient aux surfaces importantes et à tous les systèmes de coordonnées géographiques.
Sélectionner le type de méthode de fusion
Options permettant de spécifier la méthode de fusion. Si une méthode de fusion est choisie, vous avez la possibilité de créer des surfaces multi-parties ou à une seule partie et vous pourrez calculer des statistiques en fonction des champs fournis.
- Tous : toutes les entités sont fusionnées. Si les entités multi-parties sont autorisées, toutes les entités sont fusionnées en une seule entité. Si les entités multi-parties ne sont pas autorisées, les entités adjacentes ou superposées sont fusionnées.
- Champs : les entités qui partagent le même champ spécifié ou la même combinaison de champs spécifiée sont fusionnées. Si les entités multi-parties sont autorisées, toutes les entités dotées du même champ sont fusionnées en une seule entité. Si les entités multi-parties ne sont pas autorisées, les entités adjacentes ou superposées dotées de la même valeur de champ sont fusionnées.
- Aucun : aucune entité n'est fusionnée. Il s’agit de l’option par défaut.
Autoriser les entités multi-parties
Option permettant de spécifier si votre résultat se compose d'entités en une seule partie ou multi-parties.
- Activé : les résultats de votre analyse contiendront des entités multi-parties.
- Désactivé : les résultats de votre analyse contiendront des entités en une seule partie. Il s'agit du paramètre par défaut.
Ajouter des statistiques (facultatif)
Vous pouvez calculer des statistiques sur des entités synthétisées. Vous pouvez calculer les données suivantes sur des champs numériques :
- Total : calcule le nombre de valeurs non Null. Peut être utilisé sur des champs numériques ou des chaînes. Le total de [Null, 0, 2] est égal à 2.
- Somme : somme des valeurs numériques dans un champ. La somme de [Null, 0, 3] est égale à 3.
- Moyenne : moyenne des valeurs numériques. La moyenne de [0, 2, Null] est égale à 1.
- Min : valeur minimale d'un champ numérique. La valeur minimale de [0, 2, Null] est égale à 0.
- Max : valeur maximale d'un champ numérique. La valeur maximale de [0, 2, Null] est égale à 2.
- Plage : plage d'un champ numérique. Elle est calculée pour correspondre aux valeurs minimales soustraites de la valeur maximale. La plage de [0, Null, 1] est égale à 1. La plage de [Null, 4] est égale à 0.
- Variance : variance d'un champ numérique dans une piste. La variance de [1] est la valeur Null. La variance de [null, 1,0,1,1] est égale à 0,25.
- Ecart type : écart type d'un champ numérique. L'écart type de [1] est la valeur Null. L’écart type de [null, 1,0,1,1] est égale à 0,5.
Vous pouvez calculer les données suivantes sur des champs de type chaîne :
- Total : le nombre de chaînes différentes de la valeur Null.
- Tout : cette statistique est un échantillon aléatoire d'une valeur de chaîne dans le champ spécifié.
Choisir une instance ArcGIS Data Store dans laquelle enregistrer les résultats
Les résultats GeoAnalytics sont stockés dans un répertoire de données et s’affichent en tant que couche d’entités dans Portal for ArcGIS. Dans la plupart des cas, les résultats doivent être stockés dans le stockage des données spatio-temporelles, ce qui est le paramètre par défaut. Dans certains cas, il peut être judicieux d’enregistrer les résultats dans un répertoire de données relationnelles. Voici les raisons pour lesquelles stocker les résultats dans le répertoire de données relationnelles :
- Vous pouvez utiliser vos résultats dans le cadre d’une collaboration entre plusieurs portails.
- Vous pouvez activer la synchronisation de vos résultats
Vous ne devez pas utiliser le répertoire de données relationnelles si vous pensez que vos résultats GeoAnalytics vont augmenter et que vous devez tirer parti des fonctionnalités du répertoire de Big Data spatio-temporelles pour gérer les grands volumes de données.
Nom de la couche de résultat
Le nom de la couche à créer. Si vous écrivez dans une instance ArcGIS Data Store, vos résultats sont enregistrés dans My Content (Mon contenu) et ajoutés à la carte. Si vous écrivez dans un partage de fichiers Big Data, vos résultats sont stockés dans le partage de fichiers Big Data et ajoutés à son manifeste. Ils ne sont pas ajoutés à la carte. Le nom par défaut repose sur le nom de l'outil et sur le nom de la couche en entrée. Si la couche existe déjà, l'outil échoue.
Lors de l’écriture sur ArcGIS Data Store (répertoire de données relationnelles ou spatio-temporelles) via la zone de liste déroulante Save result in (Enregistrer le résultat dans), vous pouvez spécifier le nom d’un dossier dans My Content (Mon contenu) où le résultat sera enregistré.