Find Dwell Locations
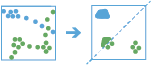
This tool works with a time-enabled layer of
point features that are of type instant. First, the tool assigns features to a track using a unique identifier. Track order is determined by the time of features. Next, the distance between the first observation in a track and the next is calculated. Features are considered to be part of a dwell if two temporally consecutive points stay within the given distance for at least the given duration. When two features are found to be part of a dwell, the first feature in the dwell is used as a reference point, and the tool finds consecutive features that are within the specified distance of the reference point in the dwell. Once all features within the specified distance are found, the tool collects the dwell features and calculates their mean center. Features before and after the current dwell are added to the dwell if they are within the given distance of the dwell location's mean center. This process continues until the end of the track.
Features in time-enabled layers can be represented in one of the following ways:
- Instant—A single moment in time
- Interval—A start and end time
For example, suppose you work for the Department of Transportation and have collected GPS readings for vehicles on major highways. Each GPS record contains a unique vehicle ID, the time, location, and speed. Using the unique vehicle ID to define individual tracks, search for vehicles that have not moved more than 100 meters in at least 15 minutes to uncover troublesome areas in the road network. Additionally, you could calculate statistics such as the mean speed of the vehicles within the dwell location.
Choose the layer to find dwells from
The point layer that will be summarized into dwells. The input layer must be time-enabled with features that represent an instant in time, as well as have one or more fields that can be used to identify tracks.
In addition to choosing a layer from your map, you can choose Choose Analysis Layer at the bottom of the drop-down list to browse to your contents for a big data file share dataset or feature layer. You may optionally apply a filter on your input layer or apply a selection on hosted layers added to your map. Filters and selections are only applied for analysis.
Select one or more fields to identify tracks
Fields that represent the track identifier. You can use one field or multiple fields to represent unique values of tracks.
For example, if you were finding dwell locations for hurricanes, you could use the hurricane name as the track field.
Choose the method to calculate distance
Method used to calculate the dwell distance within tracks. The Planar method may calculate the results more quickly but will not wrap tracks around the international date line or account for the actual shape of the earth when buffering. The Geodesic method will wrap tracks around the international date line if required and apply a geodesic buffer to account for the shape of the earth.
Define the spatial search distance
The dwell distance tolerance is the maximum distance between points to be considered in a single dwell location.
For example, if you are interested in finding dwells where traffic has not moved more than 20 meters within a certain time, the distance tolerance would be 20 meters.
Use the parameter Define the temporal search range to specify the time.
Split tracks (optional)
The unit of the distance tolerance.
Define the temporal search range
The dwell time tolerance is the minimum time duration of a dwell to be considered in a single dwell location.
For example, if you want to know where traffic hasn't moved a certain distance within an hour, the time tolerance would be 1 hour.
Use the parameter Define the spatial search range to specify the distance.
Select a distance to split tracks by (optional)
The unit of the time tolerance.
Add statistics (optional)
You can calculate statistics on features that are summarized. You can calculate the following on numeric fields:
- Count—Calculates the number of nonnull values. It can be used on numeric fields or strings. The count of [null, 0, 2] is 2.
- Sum—The sum of numeric values in a field. The sum of [null, null, 3] is 3.
- Mean—The mean of numeric values. The mean of [0, 2, null] is 1.
- Min—The minimum value of a numeric field. The minimum of [0, 2, null] is 0.
- Max—The maximum value of a numeric field. The maximum value of [0, 2, null] is 2.
- Range—The range of a numeric field. This is calculated as the minimum values subtracted from the maximum value. The range of [0, null, 1] is 1. The range of [null, 4] is 0.
- Variance—The variance of a numeric field in a track. The variance of [1] is null. The variance of [null, 1,0,1,1] is 0.25.
- Standard deviation—The standard deviation of a numeric field. The standard deviation of [1] is null. The standard deviation of [null, 1,0,1,1] is 0.5.
- First—The first value of a specified field in the summarized track. If a track has the following time-ordered values for a field: [1,5,10,20], the first value is 1.
- Last—The last value of a specified field in the summarized track. If a track has the following time-ordered values for a field: [1,5,10,20], the last value is 20.
You can calculate the following on string fields:
- Count—The number of nonnull strings.
- Any—This statistic is a random sample of a string value in the specified field.
- First—The first value of a specified field in the summarized track. If a track has the following time-ordered values for a field: [Toronto,Guelph,Squamish,Montreal,Halifax,Redlands,Boston], the first value is Toronto.
- Last—The last value of a specified field in the summarized track. If a track has the following time-ordered values for a field: [Toronto,Guelph,Squamish,Montreal,Halifax,Redlands,Boston], the last value is Boston.
Output dwell locations as
Determines which features are returned and the format. Four types are available:
- Mean Centers—A point representing the centroid of each discovered dwell location. Attributes will be summarized. This is the default.
- Convex Hulls—Polygons representing the convex hull of each dwell group. Attributes will be summarized.
- Dwell Features—All of the input point features and attributes determined to belong to a dwell are returned.
- All Features—All of the input point features and attributes are returned.
Analyze data with time intervals (optional)
Specify if you want to look for dwell locations using time intervals which segment your input features for analysis. If you use time intervals you must set the time interval you want to use, and optionally set the reference time. If you don't set a reference time, Jan 1, 1970 will be used.
For example, if you set the time boundary to be 1 day, starting at 9:00 AM on January 1st, 1990, than each track will be truncated at 9:00 am for every day and analyzed within that segment. No dwells will start before 9:00 AM and end afterwards.
Using time intervals is a fast way to accelerate computing time, as it quickly creates smaller tracks for analysis. If splitting by a reoccurring time interval makes sense for your analysis, it is recommend for big data processing.
Result layer name
The name of the layer that will be created. If you are writing to an ArcGIS Data Store, your results will be saved in My Content and added to the map. If you are writing to a big data file share, your results will be stored in the big data file share and added to its manifest. They will not be added to the map. The default name is based on the tool name and the input layer name. If the layer already exists, the tool will fail.
When writing to ArcGIS Data Store (relational or spatiotemporal big data store) using the Save result in drop-down box, you can specify the name of a folder in My Content where the result will be saved.