Найти местоположения задержек
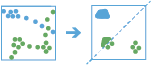
Этот инструмент работает со слоем точечных объектов типа instant; в слое поддерживается функция времени. Во-первых, инструмент назначает объекты треку с помощью уникального идентификатора. Порядок трека определяется временем появления объектов. Затем вычисляется расстояние между первым и следующим наблюдением в треке. Пространственные объекты считаются частью задержки, если две последовательно расположенные во времени точки остаются в пределах заданного расстояния в течение, по крайней мере, заданного времени. При обнаружении двух объектов, являющихся частью задержки, первый объект в задержке используется в качестве исходной точки, и инструмент находит последовательные объекты, находящиеся в пределах указанного расстояния от исходной точки в задержке. Как только все объекты в пределах указанного расстояния найдены, инструмент собирает объекты задержки и вычисляет их усредненный центр. Объекты до и после текущей задержки добавляются к задержке, если они находятся в пределах заданного расстояния от местоположения усредненного центра задержки. Этот процесс продолжается до конца трека.
Объекты слоев с поддержкой времени могут быть представлены следующими способами:
- Текущий момент – один момент времени
- Интервал – время начала и время окончания
Например, предположим, что вы работаете в Департаменте транспорта и собрали показания GPS для транспортных средств на основных автомагистралях. Каждая запись GPS содержит уникальный идентификатор автомобиля, время, местоположение и скорость. Используя уникальный идентификатор транспортного средства для определения отдельных треков, найдите автомобили, которые не передвигались более чем на 100 метров в течение как минимум 15 минут, чтобы обнаружить проблемные участки в дорожной сети. Кроме того, вы можете рассчитать статистику, такую как средняя скорость транспортных средств в пределах места задержки.
Выберите слой, в котором нужно найти задержки, из
Точечного слоя, который будет просуммирован в задержки. Входным слоем должен быть слой с активированным временем, с объектами, представляющими определенный момент времени, а также содержать одно или несколько полей, которые можно использовать для идентификации треков.
Кроме выбора слоя из вашей карты, можно щелкнуть Выбрать слой анализа в нижней части ниспадающего списка, чтобы найти свои ресурсы для набора данных или векторного слоя файлового хранилища больших данных. Вы можете дополнительно применить к входному слою фильтр или выборку к размещенным векторным слоям, добавленным на карту. Фильтры и выборки будут применяться только к процессу анализа.
Выберите одно или более полей для идентификации треков
Поля, представляющие идентификатор трека. Для представления уникальных значений трека можно использовать одно или несколько полей.
Например, если вы находите места задержек ураганов, вы можете использовать название урагана в качестве имя поля трека.
Выберите метод вычисления расстояния
Метод, используемый для расчета расстояния задержек в треках. Метод Плоский быстрее вычисляет результаты, но не может построить треки, пересекающие линию перемены дат и не учитывает при буферизации реальную форму Земли. Метод Геодезический может создавать треки, пересекающие линию перемены дат и использует геодезический буфер с учетом формы Земли.
Определить расстояние пространственного поиска
Допуск расстояния задержки – это максимальное расстояние между точками, относящимися к одному местоположению задержки.
Например, если вы заинтересованы в поиске участка задержек, на котором автомобили не перемещались более чем на 20 метров в течение определенного времени, допуск на расстояние составит 20 метров.
Используйте параметр Задайте диапазон поиска по времени, чтобы указать время.
Разделение треков (дополнительно)
Единицы допуска расстояния.
Задайте диапазон поиска по времени
Допуск времени задержки – это минимальная продолжительность времени задержки, которое следует учитывать в одном месте.
Например, если вы хотите знать, где трафик не перемещался на определенное расстояние в течение часа, время допуска будет равно 1 часу.
Используйте параметр Задайте диапазон пространственного поиска, чтобы указать расстояние.
Выбрать расстояние для разбиения треков (дополнительно)
Единица допуска времени.
Добавить статистику (дополнительно)
Вы можете вычислить статистику по суммируемым объектам. Вы можете вычислить следующее для числовых полей:
- Количество – вычисляет количество ненулевых значений. Может использоваться с числовыми или текстовыми полями. Количество [null, 0, 2] – это 2.
- Сумма – сумма числовых значений в поле. Сумма [null, null, 3] равна 3.
- Среднее – среднее арифметическое числовых значений. Среднее [0, 2, null] равно 1.
- Мин – минимальное значение числового поля. Минимальное значение [0, 2, null] равно 0.
- Макс – максимальное значение числового поля. Максимальное значение [0, 2, null] равно 2.
- Диапазон – диапазон числового поля. Он вычисляется вычитанием минимального значения из максимального. Диапазон [0, null, 1] равен 1. Диапазон [null, 4] равен 0.
- Дисперсия – дисперсия по числовому полю в треке. Дисперсия [1] равна null. Дисперсия [null, 1,0,1, 1] равна 0,25.
- Среднеквадратическое отклонение – среднеквадратическое отклонение числового поля. Среднеквадратическое отклонение [1] равно null. Среднеквадратическое отклонение [null, 1,0,1, 1] равно 0,5.
- Первое – Первое значение указанного поля в суммированном треке. Если трек содержит следующие значения хронологии для поля: [1,5,10,20], первым значением будет 1.
- Последнее – Последнее значение указанного поля в суммированном треке. Если трек содержит следующие значения хронологии для поля: [1,5,10,20], последним значением будет 20.
Вы можете вычислить следующее для числовых полей:
- Количество – количество не пустых строк.
- Любая – эта статистика является случайной выборкой строкового значения в указанном поле.
- Первое – Первое значение указанного поля в суммированном треке. Если трек содержит следующие значения хронологии для поля: [Toronto,Guelph,Squamish,Montreal,Halifax,Redlands,Boston], первым значением будет Toronto.
- Последнее – Последнее значение указанного поля в суммированном треке. Если трек содержит следующие значения хронологии для поля: [Toronto,Guelph,Squamish,Montreal,Halifax,Redlands,Boston], последним значением будет Boston.
Выгрузить местоположения задержек как
Определяет, какие возвращаются пространственные объекты и формат. Доступны четыре типа:
- Усредненные центры – точка, представляющая центроид каждого обнаруженного места задержки. Атрибуты будут суммированы. Используется по умолчанию.
- Выпуклые оболочки – полигоны, представляющие выпуклую оболочку каждой группы задержек. Атрибуты будут суммированны.
- Объекты задержек – возвращаются все входные точечные объекты и атрибуты, определенные как принадлежащие задержке.
- Все объекты – возвращаются все входные точечные объекты и атрибуты.
Анализ данных с временными интервалами (дополнительно)
Укажите, хотите ли вы для поиска местоположений задержек использовать временные интервалы, которые разделяли бы входные объекты для анализа. Если вы используете интервалы, необходимо задать его, а также, дополнительно, настроить базовое время. Если базовое время не настроено, используется 1 января 1970.
Например, если вы выбрали интервал в 1 день, начиная с 9:00 1 января 1990, каждый трек будет обрезан в 9:00 каждого дня и проанализирован в пределах этого сегмента. Никакие задержки не будут начинаться до 9:00 утра, заканчиваясь после этого.
Использование интервалов позволяет ускорить обработку, т.к. небольшие треки для анализа создаются быстрее. Если разбиение на повторяющиеся интервалы может влиять на результаты анализа, рекомендуется использовать обработку больших данных.
Имя слоя результата
Имя создаваемого слоя. Если вы записываете в ArcGIS Data Store, ваши результаты будут сохранены в Моих ресурсах и добавлены на карту. Если вы записываете в файловое хранилище больших данных, ваши результаты будут сохранятся в файловом хранилище больших данных и добавляться в его файл манифеста. Они не будут добавлены на карту. Имя слоя по умолчанию зависит от имени инструмента и имени входного слоя. Если слой уже существует, произойдет сбой.
При записи в ArcGIS Data Store (реляционное или пространственно-временное хранилище больших данных) с помощью ниспадающего списка поля Сохранить результат в вы можете задать имя папки в разделе Мои ресурсы, в которую будет записан результат.