Woonlocaties zoeken
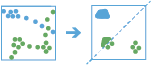
Deze tool werkt met een tijdgestuurde laag van puntobjecten van het type instant. Allereerst wijst de tool objecten toe aan een track met behulp van een unieke identifier. De trackvolgorde wordt bepaald door de tijd van objecten. Vervolgens wordt de afstand tussen de eerste observatie en de volgende in een track berekend. Objecten worden gezien als onderdeel van een woning als binnen de bepaalde tijd twee temporele opeenvolgende punten binnen de bepaalde afstand blijven. Als er twee objecten onderdeel blijken van een woning, wordt het eerste object in de woning gebruikt als een referentiepunt en de tool vindt opeenvolgende objecten die zich binnen de gespecificeerde afstand van het referentiepunt in de woning bevinden. Als alle objecten binnen de gespecificeerde afstand eenmaal zijn gevonden, verzamelt de tool de woonobjecten en berekent hun gemiddelde centrum. Objecten voor en na de huidige woning worden toegevoegd aan de woning als ze binnen de gegeven afstand van het gemiddelde centrum van de woonlocatie liggen. Dit proces gaat door tot het einde van de track.
Objecten in tijdgestuurde lagen kunnen worden weergegeven op de volgende manieren:
- Direct—Eén moment in de tijd
- Interval—Een start- en eindtijd
Stel dat u voor de Afdeling Transportatie werkt en GPS-gegevens hebt verzameld voor voertuigen op grote snelwegen. Elke GPS-record bevat een unieke voertuig-ID, de tijd, locatie en de snelheid. Met behulp van de unieke voertuig-ID om individuele tracks te definiëren, zoekt u naar voertuigen die in de afgelopen 15 minuten niet meer dan 100 meter zijn verplaatst, om knelpunten in het wegennetwerk te ontdekken. Daarnaast kunt u statistieken berekenen zoals de gemiddelde snelheid van de voertuigen binnen de woonlocatie.
Kies de laag om woningen in te zoeken
De puntlaag die wordt samengevat in woningen. De invoerlaag moet tijdgestuurd zijn met objecten die een moment in de tijd vertegenwoordigen, evenals een of meer velden die kunnen worden gebruikt om tracks te identificeren.
Naast het kiezen van een laag van uw kaart, kunt u kiezen voor Analyselaag kiezen onderaan de keuzelijst om in uw inhoud te zoeken naar een big data file share-dataset of objectlaag. U kunt optioneel een filter toepassen op uw invoerlaag of een selectie toepassen op gehoste lagen die aan uw kaart zijn toegevoegd. Filters en selecties worden alleen toegepast voor analyse.
Selecteer een of meer velden om track te identificeren
Velden die de trackidentifier vertegenwoordigen. U kunt één veld of meerdere velden gebruiken om unieke waarden van tracks te representeren.
Bijvoorbeeld als u de locaties waar orkanen zich bevinden zoekt, kunt u de naam van de orkaan gebruiken als het trackveld.
Kies de methode om de afstand te berekenen
Methode die wordt gebruikt om de woningafstand binnen tracks te berekenen. De Planaire methode kan de resultaten sneller berekenen, maar wikkelt de tracks niet rond de internationale datumlijn en houdt geen rekening met de daadwerkelijke vorm van de aarde bij het bufferen. De Geodetische methode wikkelt tracks rond de internationale datumlijn indien nodig en past een geodetische buffer toe om rekening te houden met de vorm van de aarde.
De ruimtelijke zoekafstand definiëren
De tolerantie van de woningafstand is de maximale afstand tussen punten die zich in een enkele woonlocatie bevinden.
Als u bijvoorbeeld geïnteresseerd bent in het zoeken van woningen waar het verkeer binnen een bepaalde tijd niet meer dan 20 meter heeft bewogen , zou de afstandslocatie 20 meter zijn.
Gebruik de parameter Het tijdelijke zoekbereik definiëren om de tijd op te geven.
Splitsen van tracks (optioneel)
De eenheid van de afstandstolerantie.
Het tijdelijke zoekbereik definiëren
De tijdstolerantie van de woning is de minimale tijd van een woning die zich in een enkele woonlocatie bevindt.
Als u bijvoorbeeld wilt weten waar verkeer een bepaalde afstand niet heeft afgelegd binnen een uur, zet u de tijdstolerantie op 1 uur.
Gebruik de parameter Het ruimtelijke zoekbereik definiëren om de afstand op te geven.
Selecteer een afstand om traceringen op te splitsen (optioneel)
De eenheid van de tijdstolerantie.
Statistieken toevoegen (optioneel)
U kunt statistieken berekenen over objecten die zijn samengevat. U kunt het volgende berekenen in numerieke velden:
- Count—Berekent het aantal non-nulwaarden. Kan gebruikt worden op numerieke velden of strings. De telling van [nul, 0, 2] is 2.
- Som—De som van numerieke waarden in een veld. De som van [nul, nul, 3] is 3.
- Gemiddelde—Het gemiddelde van numerieke waarden. Het gemiddelde van [0, 2, nul] is 1.
- Min—De minimumwaarde van een numeriek veld. Het minimum van [0, 2, nul] is 0.
- Max—De maximumwaarde van een numeriek veld. De maximumwaarde van [0, 2, nul] is 2.
- Bereik—Het bereik van een numeriek veld. Dit wordt berekend als de minimumwaarden afgetrokken van de maximumwaarde. Het bereik van [0, nul, 1] is 1. Het bereik van [nul, 4] is 0.
- Variantie—De variantie van een numeriek veld in een track. De variantie van [1] is nul. De variantie van [null, 1,0,1,1] is 0,25.
- Standaarddeviatie—De standaarddeviatie van een numeriek veld. De standaarddeviatie van [1] is nul. De standaarddeviatie van [null, 1,0,1,1] is 0,5.
- Eerste—De eerste waarde van een gespecificeerd veld in de samengevatte track. Als een track de volgende tijdsgeordende waarden voor een veld heeft: 1,5,10,20], is de eerste waarde 1.
- Laatste—De laatste waarde van een gespecificeerd veld in de samengevatte track. Als een track de volgende tijdsgeordende waarden voor een veld heeft: 1,5,10,20], is de laatste waarde 20.
U kunt het volgende berekenen in stringvelden:
- Telling—Het aantal non-nul strings.
- Elke—Deze statistiek is een willekeurig voorbeeld van een stringwaarde in het gespecificeerde veld.
- Eerste—De eerste waarde van een gespecificeerd veld in de samengevatte track. Als een track de volgende tijdsgeordende waarden voor een veld heeft: [Toronto,Guelph,Squamish,Montreal,Halifax,Redlands,Boston], is de eerste waarde Toronto.
- Laatste—De laatste waarde van een gespecificeerd veld in de samengevatte track. Als een track de volgende tijdsgeordende waarden voor een veld heeft: [Toronto,Guelph,Squamish,Montreal,Halifax,Redlands,Boston], is de laatste waarde Boston.
Voer woongebieden uit als
Bepaalt welke objecten worden uitgevoerd en het formaat. Er zijn vier typen beschikbaar:
- Gemiddelde centra—Een punt dat het zwaartepunt van elke woonlocatie representeert. Attributen worden samengevat. Dit is de standaardinstelling.
- Convex Hulls—Vlakken die een convex hull van elke woninggroep representeren. Attributen worden samengevat.
- Woonobjecten—Alle ingevoerde puntobjecten en attributen waarvan bepaald is dat ze bij een woning horen, worden uitgevoerd.
- Alle objecten—Alle ingevoerde puntobjecten en attributen worden uitgevoerd.
Analyseer gegevens met tijdsintervallen (optioneel)
Geef aan of u woonlocaties wilt zoeken met tijdsintervallen die uw invoerobjecten segmenteren voor analyse. Als u tijdsintervallen gebruikt, moet u het tijdsinterval dat u wilt gebruiken instellen en optioneel de referentietijd instellen. Als u geen referentietijd instelt, wordt 1 januari 1970 gebruikt.
Als u bijvoorbeeld de tijdgrens instelt als 1 dag, beginnend om 9:00 op 1 januari 1990, dan wordt elke track afgekapt om 9.00 uur voor elke dag en geanalyseerd binnen dat segment. Geen enkele woonlocatie begint voor 9.00 uur 's morgens en eindigt daarna.
Het gebruik van tijdsintervallen is een snelle manier om de rekentijd te versnellen, omdat het snel kleinere tracks voor analyse creëert. Als splitsen met een terugkerend tijdsinterval zinvol is voor uw analyse, is het aan te raden voor de verwerking van big data.
Resultaat laagnaam
De naam van de laag die wordt gemaakt. Als u naar een ArcGIS Data Store schrijft, worden uw resultaten opgeslagen in Mijn Content en toegevoegd aan de kaart. Als u naar een big data file share schrijft, worden uw resultaten opgeslagen in de big data file share en toegevoegd aan het bijhorende manifest. Ze zullen niet worden toegevoegd aan de kaart. De standaardnaam is gebaseerd op de toolnaam en de naam van de invoerlaag. Als de laag al bestaat, zal de tool falen.
Wanneer u schrijft naar ArcGIS Data Store (relationele of spatiotemporele big datastore) met behulp van de vervolgkeuzelijst Resultaat opslaan in, kunt u de naam van een map opgeven in Mijn Content, waar het resultaat wordt opgeslagen.